RAG에서 한국어 OCR(Clova OCR, Upstage, Llama Parse) 써보기
(24년 12월 추가)
글 내용과 관련해 강의를 런칭하였습니다. 더 많은 정보가 필요하신 분들은 참고해주세요!!
▪ 쿠폰코드: PRDTEA241202_auto
▪ 할인액: 4만원 (~25/1/5 까지 사용가능)
▪ 강의링크: https://bit.ly/3BayH1F
제가 직접 작성한 것이 아닌 AutoRAG를 같이 만든 김병욱 연구원이 쓴 글입니다.
들어가며
RAG에선 정말 여러 특징을 가진 문서들을 마주하게 되고, 이를 코퍼스로 사용하기 위해 파싱한다.
이 세상에 오직 텍스트로만 이루어진 문서 밖에 없어서 이 문서로만 RAG를 만들 수 있다면 좋겠지만, 전혀 그렇지 않다
두껍고 복잡한 규정을 다루는 문서들일 수록 복잡한 표로 이루어져 있고, 아래의 사진처럼 국내 문서들은 유독 더 특이하고 복잡한 표들이 많다 😂😂

이런 복잡한 문서들로 코퍼스로 만들어야 할 때, OCR로 표 정보를 추출하는 방법을 사용하곤 한다.
한국어 OCR의 대표 주자인 클로바의 OCR과 업스테이지 OCR, 그리고 질문을 많이 받은 라마인덱스의 llama parse까지 3가지 OCR로 PDF 문서를 파싱하며 느낀 점들을 간단히 공유해보고자 한다 😁
1. Clova OCR
먼저, 🍀네이버의 클로바 OCR🍀
한국어를 잘 하는 OCR하면 가장 먼저 네이버의 클로바 OCR과, 업스테이지의 OCR을 많이들 얘기한다.
특히, 클로바 OCR은 지난 PDF 라이브러리 vs 네이버 Clova OCR에서 다루면서 한번 공유했던 적이 있다
해당 실험에서 클로바 OCR은 좋은 성능을 보여줬었다.
특히, 복잡한 표 안의 표까지 잘 인식해내는 모습에 놀랐었다.
지난 실험에서는 클로바 OCR을 웹 데모로만 사용해보았었는데, 이번에는 API로 직접 사용해보며 RAG를 위한 문서 파싱을 해보았다.
이 과정에서 느꼈던 점들과 사용성 위주로 적어보고자 한다.
1-1. PDF문서를 페이지마다 이미지로 만들어주어야 한다.
34페이지 짜리 PDF 파일 1개가 있으면, 34개의 이미지 파일로 먼저 만들어줘야 하는 것이다.
과정이 늘어나기는 하지만, 이는 그렇게까지 불편하지는 않았다.
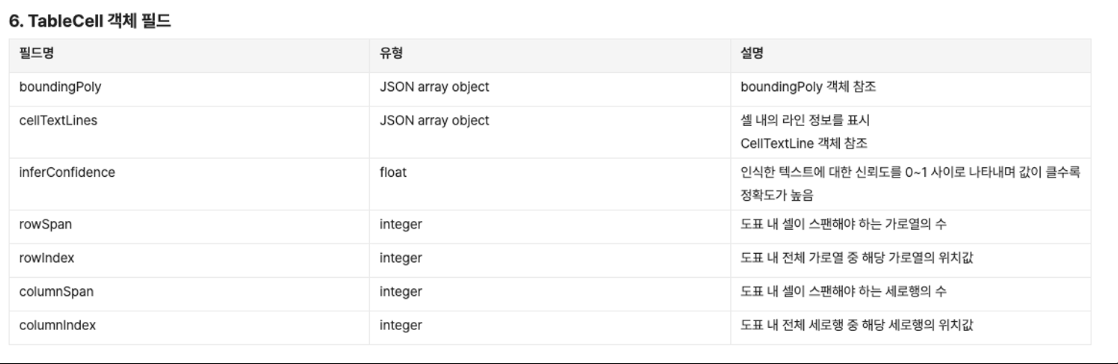
1-2. 표 정보를 복잡한 JSON으로 받는다.
RAG에서 프롬프트에 표 정보를 넣을 때 사용할 수 있는 방법은 여러가지가 있다.
표 정보를 넣어줄 때, 크게 JSON, Markdown, HTML을 많이 사용하는데, 경험적으로는 HTML로 넣어줄 때가 가장 괜찮은 성능을 보여주었다.
⚠️ 물론 경험적으로만 검증된 정보이기 때문에, 여러 방법론들과 함께 실험을 통해 확실히 검증해볼 계획이다 :)

클로바 OCR에서 표 정보는 다음과 같이 온다.
JSON이긴 하지만, 다음과 같이 복잡한 JSON을 LLM이 이해하기는 너무 어렵다.
그래서 저 복잡한 JSON을 HTML로 바꿔주는 작업이 필요하다
API 가이드가 있긴 했지만, JSON이 복잡하게 생겨서 HTML로 바꿔주는 데 작업이 좀 필요했다.
1-3. 표 + 텍스트로 이루어진 경우, 텍스트 정보와 표 정보가 따로 온다.
- 원본 문서
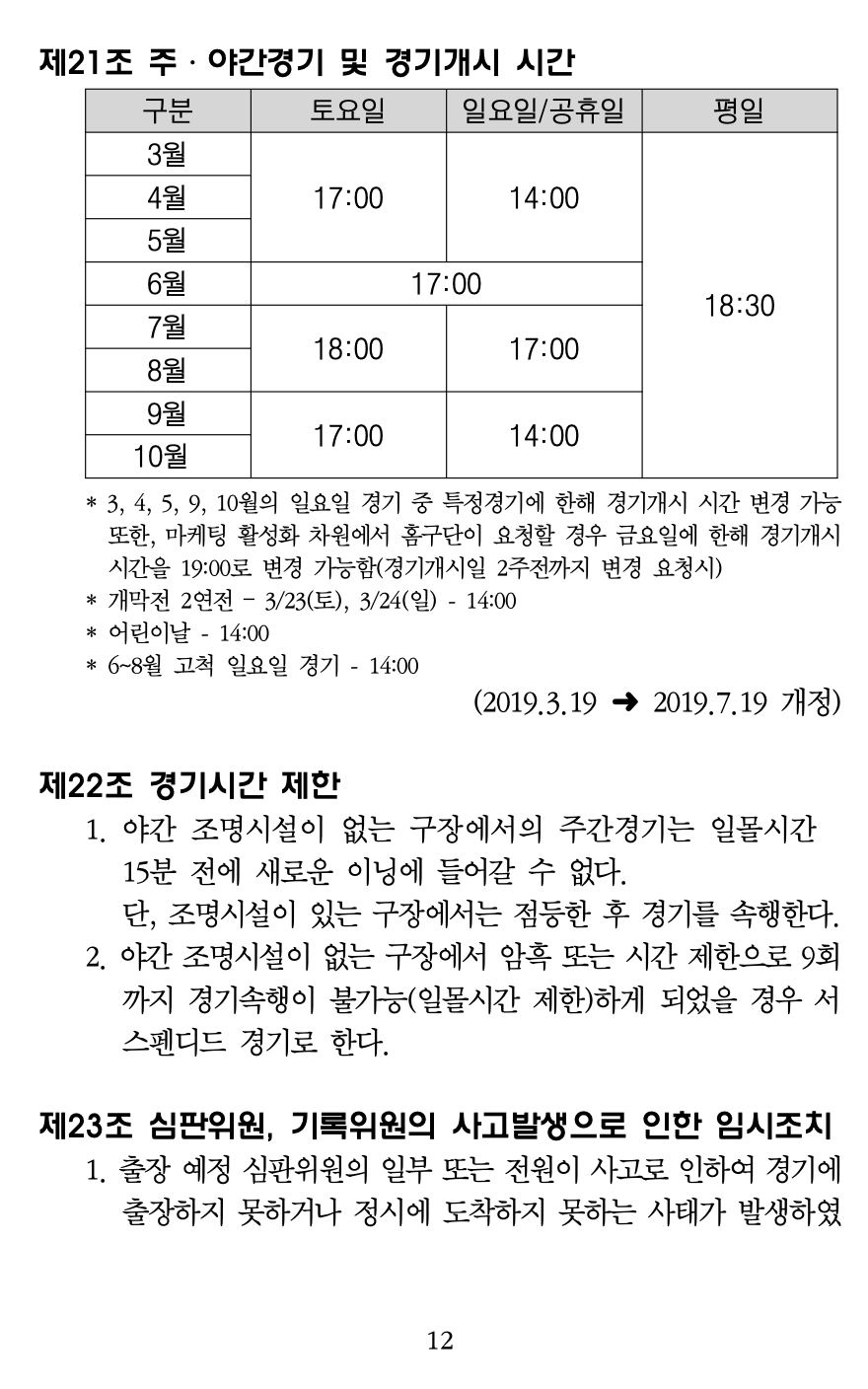
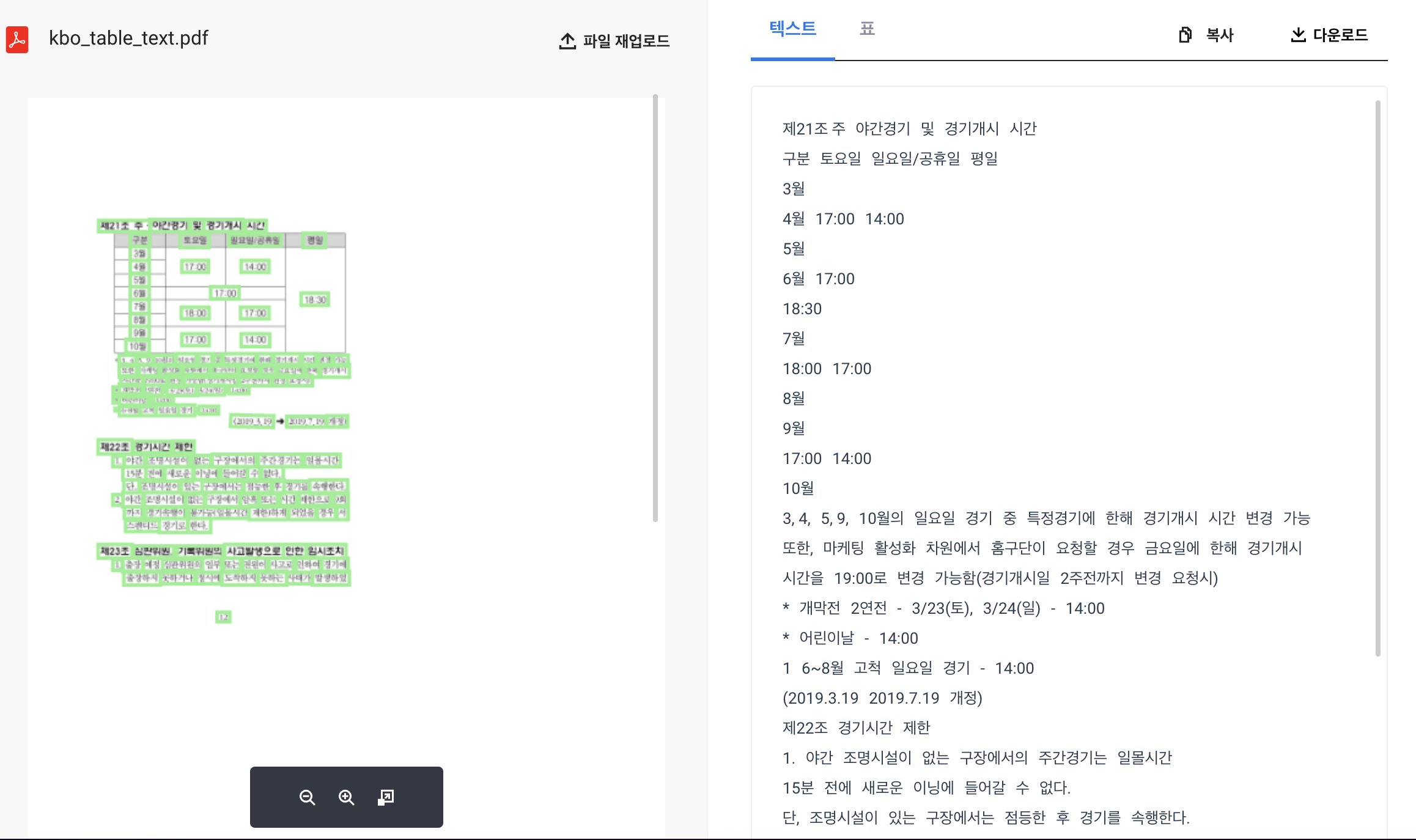
위의 페이지를 클로바 OCR로 파싱을 하면, 텍스트와 표 정보가 따로 온다.
-
텍스트 정보
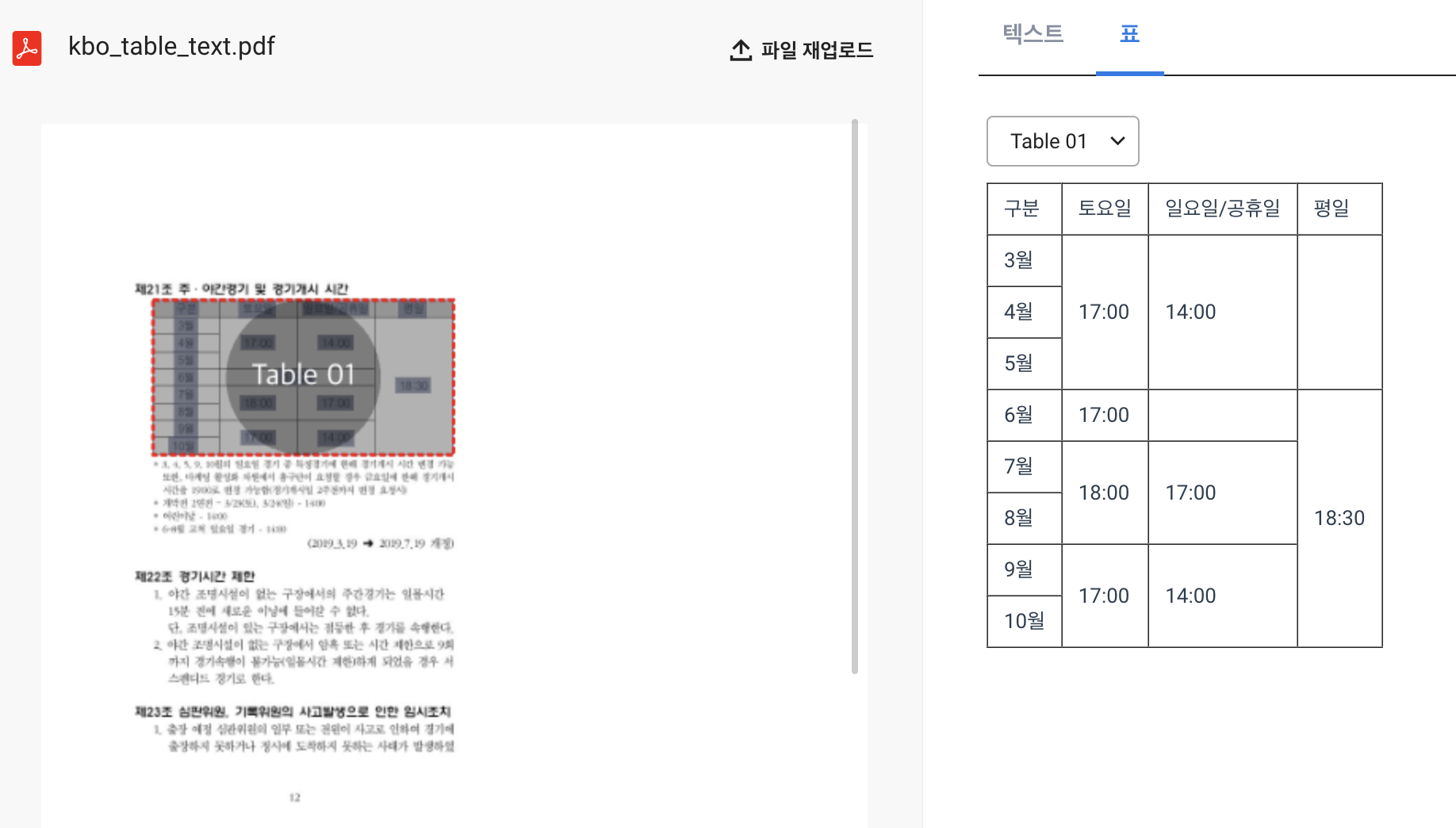
-
표 정보
만약 텍스트 + 표 + 텍스트와 같은 구조라면,
표의 적절한 위치를 찾아서 넣어주는 작업을 해주거나,
아니면 텍스트 정보 + 표 정보 처럼 따로 저장해주어야 한다.
추가적으로, API로 돌렸을 때랑 웹 데모로 추출 결과값이 다르게 나오는 이슈가 있었다.
똑같은 V2를 사용했고, general template를 사용했는데 다른 결과값을 얻었다.!
혹시 비슷한 증상을 겪은 분들이 있거나 이유를 아는 분들이 있다면, 댓글 부탁드립니다 !!
2. Upstage LayoutAnalysis
다음으로 업스테이지.
업스테이지 홈페이지에 들어가면 다음과 같이 3개의 DocumentAI가 있다.
내가 OCR을 쓰는 이유는 표를 추출하기 위해서라서 첫 번째 Layout Anlysis를 사용해주었다.
2-1. 표 정보를 HTML로 받는다
따로 파서를 제작해줄 필요 없이, 바로 HTML로 결과값을 받아볼 수 있다.
2-2. 표 + 텍스트도 한번에 받는다
-
원본 문서

-
파싱 결과

제목 + 표 인데도 함께 잘 파싱한 것을 확인할 수 있다.
예를들어,
- ‘제목 + 표 + 텍스트’,
- ‘텍스트 + 표 + 텍스트’
인 경우에도 표의 위치까지 정확한 결과 값을 받을 수 있다.
2-3. Langchain에서 지원
langchaind의 document loaders에서 업스테이지의 LayoutAnalysis를 지원한다.

API KEY만 발급 받으면 쉽게 사용할 수 있다.
표에서 텍스트 추출 성능은 비슷비슷한데, RAG용으로 파싱을 할 때는 가장 사용하기 편했다.
표 + 텍스트도 함께 받을 수 있다는 게 RAG에 있어서 최대 장점이라고 느꼈다.
3. llama Parse
마지막으로는 🦙 라마인덱스의 llama parse 🦙
llama parse의 지원 언어에 한국어가 있기도 하고, 개인적으로는 llama parse의 한국어 성능이 어느정도 되는 지 질문도 많이 받았다.
3-1. result type으로 markdown, text, json을 지원한다.
markdown으로 result 결과가 나오기 때문에 table 추출도 할 수 있다.
3-2. 표 + 텍스트도 한번에 받는다
라마 파서도 업스테이지와 마찬가지로 텍스트와 표를 한번에 받을 수 있다.
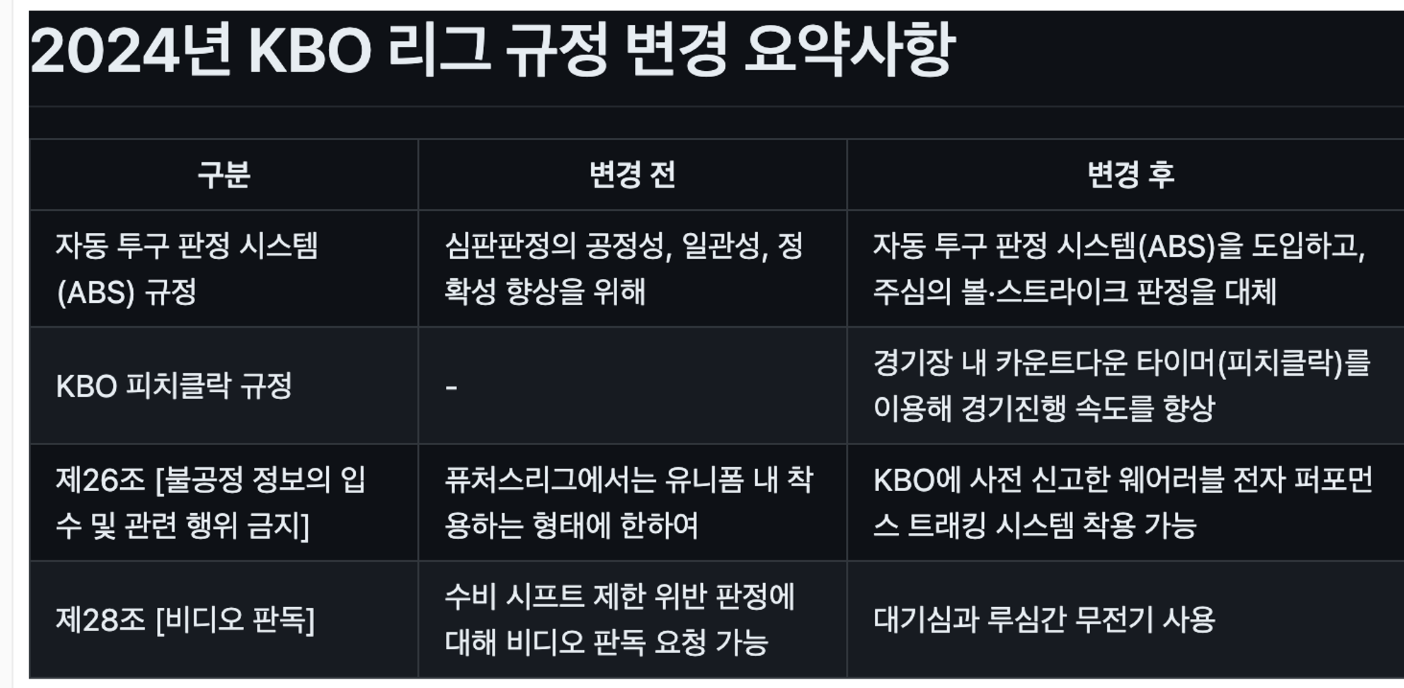
역시, 제목 + 표 인데도 함께 잘 파싱한 것을 확인할 수 있다.
예를들어,
- ‘제목 + 표 + 텍스트’,
- ‘텍스트 + 표 + 텍스트’
인 경우에도 표 파싱 결과와 텍스트 파싱 결과를 함께 받을 수 있다.
3-3. 한국어 성능이 클로바 OCR, 업스테이지 LayoutAnalysis 보다는 떨어진다.
위의 결과(원본 문서에서 변경 전에는 아무 표시도 없었지만, 파싱 결과 값에는 있는 모습)에서 볼 수 있듯, 한국어에서는 앞의 두 OCR모델 보다는 떨어지는 모습을 보인다.
다른 문서들로도 정성적으로 평가를 해보았는데, 한국어 실력이 앞의 두 모델들 보다는 살짝 떨어진다는 느낌을 받았다.